Microservices Done Right: Design Patterns, Trade-offs, and Why Apache Kafka Is the Unsung Hero
by Peter Istratov
Hi, I’m Peter Istratov — CTO, tech architect, and someone who’s spent over a decade building and scaling distributed systems, managing engineering teams, and helping startups navigate complex IT landscapes. Along the way, I’ve worn many hats: developer, team lead, head of developer, and occasional chaos tamer.
My experience spans designing scalable architectures, leading technical hiring, and even integrating products into platforms like Microsoft AppSource. I’ve built systems that handle high loads, orchestrated microservices that don’t scream at each other (too much), and embraced tools like Kafka to bring order to the madness.
My mission? To share insights, practical advice, and lessons learned the hard way, so you can focus on building robust systems — and maybe even enjoy the process.
Let’s dive into the world of distributed systems together! 🚀
System Design Is Not for the Weak
System design is one of those things that separates the dreamers from the doers, the theorists from the pragmatists. It’s like assembling IKEA furniture but at planetary scale — if one screw (or, let’s say, one service) goes missing, the entire thing topples over in production, usually at 3 a.m.
Now throw microservices into the mix. They sound like a dream — small, independent services, each doing its own thing, scaling effortlessly — but soon you realize they’re more like an unruly family of teenagers. Each one demands attention, claims independence, and creates chaos when they need to “talk” to each other.
Why do we even bother, then? Because when designed correctly, microservice architectures are elegant, scalable, and fault-tolerant. They are the foundation of some of the largest systems in the world, from Netflix’s streaming platform to Uber’s ride-hailing app. But let’s be real — this elegance doesn’t come for free.
Here’s the deal:
- Design matters. Poor system design will haunt you like a ghost in production.
- Trade-offs are inevitable. There’s no “one-size-fits-all” architecture. Choosing microservices, monoliths, or event-driven systems requires understanding the problem you’re solving.
- Communication is key. In distributed systems, reliable communication between services is half the battle. Mess this up, and you’ve got downtime, data inconsistency, and developers crying into their keyboards.
And this is where Kafka comes in.
If microservices are the noisy teenagers, then Kafka is the patient mediator who ensures everyone gets to talk asynchronously without yelling over each other. It’s the backbone of modern distributed systems — keeping things flowing, decoupling services, and helping you avoid creating a tangled spaghetti architecture.
In this article, I’ll walk you through:
- How to approach system design for scalable applications.
- Key design patterns that will save your life (or at least your deadlines).
- How Kafka can solve real-world problems, like event-driven communication, decoupling, and fault tolerance.
- Step-by-step tutorial for installing and setting up Kafka with Node.js
But this isn’t going to be just another dry, theoretical deep dive. I’ll sprinkle in real-world lessons, candid observations, and the occasional “I wish I knew this sooner” moment. Because, let’s face it — system design is not for the weak, but with the right mindset (and a little Kafka magic), you’ll feel like you’re orchestrating a symphony instead of putting out fires.
Let’s dive in. 🚀
Microservices: Breaking Things Into Smaller Problems
If you’ve ever tried to move a giant, heavy piece of furniture up a flight of stairs, you know that the process is exponentially easier when you break it down into smaller pieces. The same concept applies to monolithic applications — those single, massive codebases where every functionality is bundled together like a tangled ball of yarn.
Why Microservices Exist: The Monolith Problem
Monoliths are like that old, creaky wardrobe:
- Hard to move (deployment becomes a nightmare).
- Hard to scale (you can’t scale just one part — you scale the entire thing).
- Hard to modify (a tiny change in one corner risks breaking everything).
And when your business grows, the monolith starts to show cracks:
- Your deployments slow down.
- Teams step on each other’s toes because every small change affects the entire system.
- Scaling becomes expensive because you can’t isolate and scale just one function — it’s all or nothing.
This is why the industry shifted toward microservices architecture — a design approach where your application is broken down into small, loosely coupled services, each responsible for a single functionality. It’s not just about splitting code; it’s about changing the way systems are designed, developed, deployed, and scaled.
What Are Microservices, Really?
Microservices are small, independent services that work together to deliver a larger application. Each service:
- Has a single responsibility: One job, and one job only (following the Single Responsibility Principle).
- Is loosely coupled: Services communicate but don’t depend on each other’s internals.
- Is deployable independently: You can deploy one service without touching the others.
- Can be scaled independently: If one service gets hammered by traffic (e.g., payments or search), you can scale just that service.
Microservices make your life easier in the long run, but the path to get there isn’t all roses and sunshine.
The Benefits of Microservices
Microservices come with undeniable benefits, but let’s look at them through the lens of real-world problems:
- Scalability:
Imagine your service has a search functionality that suddenly gets 10x the traffic. In a monolith, you’d scale the entire system — database, user management, reporting — just to keep search afloat. In a microservices world, you scale only the search service.
It’s like putting more engines on one train car instead of pulling the entire train faster.
2. Independent Deployments:
Each microservice can be deployed on its own schedule. If a bug is found in the payments service, you fix and deploy just that service, without worrying about affecting user profiles or notifications.
No more waiting for every department to finish their work before you release. If the Payments team is ready, they ship!
3. Fault Isolation:
If one service fails, it doesn’t bring down the entire system. For example, if the “Notifications” service crashes, users can still log in and make purchases.
When one lightbulb goes out, it doesn’t take down the whole city grid.
4. Flexibility in Tech Stack:
Different services can use different technologies that suit their needs. A heavy-lifting analytics service could be built in Python, while a fast, lightweight API might use Node.js.
It’s like allowing each chef in the kitchen to use their favorite knife to get the job done faster.
5. Faster Development Cycles:
Teams can work on services independently, leading to parallel development and faster release cycles. This is particularly useful for large teams spread across multiple locations.
The Challenges of Microservices
If microservices were perfect, everyone would already be using them. In reality, they come with their own set of challenges:
- Network Overhead:
Unlike monoliths, microservices communicate over the network. Every request becomes a network call, introducing latency and a potential for failures.
2. Complexity:
With great flexibility comes great responsibility. Managing 10 microservices is significantly harder than managing a single monolith. You now need:
- Service discovery
- Load balancing
- Monitoring and logging for each service
- API gateways for managing external access
3. Data Consistency:
Microservices often rely on distributed databases. Unlike a single monolithic database, achieving strong consistency across multiple services is tricky.
4. Debugging and Troubleshooting:
When something breaks, tracing the issue through multiple microservices can feel like finding a needle in a haystack. Tools like distributed tracing (Jaeger, OpenTelemetry) are required to make sense of it all.
Microservices solve your scaling problems. They also give you new ones: trying to remember what each service does, who owns it, and why it’s returning a 503 error at 3 a.m.
Communication in Microservices
Here comes the real fun — how do microservices talk to each other?
There are two main patterns:
- Synchronous Communication (Request-Response)
- Typically done via REST APIs or gRPC.
- Simple, but creates strong coupling: one service depends on the availability of another.
2. Asynchronous Communication (Event-Driven)
- Services communicate via events using message brokers like Kafka, RabbitMQ, or AWS SNS/SQS.
- This decouples services: the producer doesn’t care if the consumer is available or slow.
Kafka to the Rescue:
Kafka acts as a mediator that allows microservices to talk asynchronously. One service produces events, and others consume them at their own pace. It’s fast, fault-tolerant, and scalable.
Conclusion: Microservices Are Powerful, But Not Free
Microservices are like splitting a massive team project into smaller tasks. Everyone works independently, but coordination becomes the real challenge.
- You get scalability, flexibility, and fault isolation.
- You also inherit complexity, network issues, and the need for tools like Kafka to keep communication flowing.
In the next sections, we’ll explore the design patterns that make microservices more manageable and see how Kafka helps orchestrate the chaos into a beautifully functioning distributed system.
Stay with me — this is where things start to get really interesting. 🚀
Design Patterns in Microservice Architecture
Design patterns in microservices are like recipes in a cookbook — they don’t invent the ingredients, but they provide proven ways to combine them so your distributed system doesn’t taste like a disaster. Each pattern solves a specific challenge, whether it’s communication, consistency, or fault tolerance. But just like cooking, using the wrong recipe for the wrong problem can leave you with a mess.
Let’s break down the most essential patterns, with real-world analogies, practical examples, and, of course, a sprinkle of humor.
API Gateway Pattern
Problem: How do you manage external access to a system made up of dozens of tiny, independent services?
Solution: Use an API Gateway as a single entry point to your microservices. It routes requests to the correct service, aggregates responses, and handles things like authentication, rate-limiting, and caching.

Why It’s Useful:
- You shield your microservices from the messy outside world.
- Clients don’t need to know which service does what — they just talk to the gateway.
- It reduces chattiness by consolidating requests (useful for mobile apps).
The API Gateway is like the receptionist at a corporate office. Instead of asking each department where HR is, you just tell the receptionist what you want, and they send you to the right place.
Example with Node.js and Express:
const express = require('express');
const app = express();
// Mock routes
app.get('/users', (req, res) => res.send('User Service'));
app.get('/orders', (req, res) => res.send('Order Service'));
// Gateway route
app.get('/api/:service', (req, res) => {
const { service } = req.params;
if (service === 'users') return res.redirect('/users');
if (service === 'orders') return res.redirect('/orders');
res.status(404).send('Service Not Found');
});
app.listen(3000, () => console.log('API Gateway running on port 3000'));Tooling: NGINX, Kong, AWS API Gateway, or custom-built solutions like the example above.
CQRS (Command Query Responsibility Segregation)
Problem: How do you optimize your system for both reading and writing data, especially when performance requirements differ?
Solution: Separate the write model (commands) and the read model (queries).
- The Command model handles updates, inserts, and deletions.
- The Query model is optimized for fast reads.
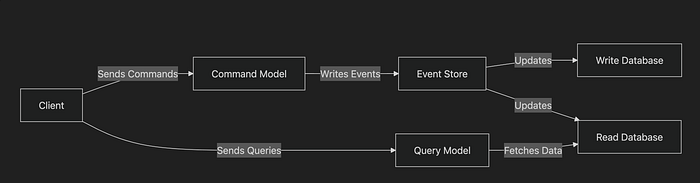
Why It’s Useful:
- You avoid overloading your database with complex queries and writes at the same time.
- It scales better under heavy read-load scenarios.
Think of a busy library: one librarian updates the book inventory (write side), while others answer your questions about available books (read side).
Example:
- Write model updates events into Kafka.
- Read model consumes these events and materializes them into a denormalized read database like Elasticsearch for fast search.
Event Sourcing
Problem: How do you track all changes to your system state and make it easy to recover or replay past events?
Solution: Instead of storing just the latest state, store a log of all events that led to that state.

How It Works:
- Each state change is recorded as an event (e.g., “OrderCreated”, “OrderPaid”).
- The current state is derived by replaying all events.
Why It’s Useful:
- Full audit trail: You know exactly what happened and when.
- Easy recovery: If your service crashes, you can replay the events to rebuild the current state.
- It works perfectly with Kafka as the event log.
It’s like rewinding a movie — Kafka stores every single scene (event), so you can replay or jump to any moment in the film.
Example Workflow:
- Producer Service emits events to Kafka:
{"event": "OrderCreated", "orderId": "123", "status": "NEW"}2. Consumer Services listen to these events and update their local databases or perform actions.
Saga Pattern
Problem: How do you handle distributed transactions across multiple microservices without locking the entire system?
Solution: Break the transaction into small steps performed by each service, with compensating actions to handle failures.

How It Works:
- A saga is a sequence of local transactions where each step triggers the next.
- If one step fails, a compensating action undoes the changes made by previous steps.
Example Scenario:
A user places an order. The following services are involved:
- Order Service → Create order (Step 1).
- Inventory Service → Reserve stock (Step 2).
- Payment Service → Process payment (Step 3).
If Step 3 fails (e.g., payment declines), a compensating action rolls back Step 2 (release inventory) and Step 1 (cancel order).
It’s like booking a vacation: if your hotel cancels, you also cancel the flight and car rental — no one wants a useless plane ticket to nowhere.
Tools to Implement Sagas:
- Orchestration: A central service coordinates the saga steps.
- Choreography: Each service emits events, and others react accordingly (works well with Kafka).
Strangler Fig Pattern
Problem: How do you gradually migrate from a monolith to microservices without halting production?
Solution: Replace parts of the monolith incrementally with microservices, while routing traffic through a facade (e.g., an API Gateway).

Why It’s Useful:
- You avoid a big bang migration, which can be risky and expensive.
- You deliver incremental value while reducing technical debt.
The pattern gets its name from the strangler fig tree, which grows around its host tree and eventually replaces it.
How It Works:
- Route traffic for specific endpoints to the new microservices.
- Gradually replace monolith components.
Example: Use an API Gateway to route /users to the old monolith while /payments hits the new microservice.
Conclusion: Choosing the Right Patterns
Design patterns in microservices are tools, not commandments. Using the wrong pattern in the wrong place can overcomplicate your system, so start simple and grow from there.
- Use API Gateway for clean entry points.
- Use CQRS and Event Sourcing for complex data flows.
- Handle transactions safely with Saga Pattern.
- Gradually escape your monolith with the Strangler Fig Pattern.
And remember: Kafka isn’t just a buzzword — it’s the glue that holds these patterns together in an event-driven architecture. Use it wisely, or prepare for consumer lag and sleepless nights.
What design patterns have you used in your microservices architecture? Share your wins, war stories, and lessons learned in comments section! 🚀

The Role of Kafka: A Microservices Therapist
Let’s get one thing straight: microservices are noisy. They talk. A lot. If you’ve ever tried to run a system with dozens of independent services sending requests back and forth, you know how quickly communication can spiral out of control. The result? Bottlenecks, delays, services dropping messages like bad habits, and developers slowly losing their sanity.
Enter Apache Kafka, the event streaming platform that acts like a therapist for your microservices: it listens, keeps things orderly, and ensures everyone gets their message without stepping on each other’s toes.
Why Do Microservices Need Kafka?
Imagine a traditional monolithic system. All components interact in-memory, and the calls are instant. But in a distributed microservices architecture, communication becomes more challenging. Services are spread across networks, and network latency, failures, and tight coupling between services create a tangled web of dependencies.
Here’s where Kafka steps in to solve the most common communication problems:
- Loose Coupling:
- In tightly coupled systems, Service A must know exactly where Service B is and wait for its response.
- Kafka decouples producers (who send messages) and consumers (who read messages). Service A just drops a message into Kafka, and Service B picks it up when it’s ready.
It’s like leaving a note on a bulletin board instead of yelling across the room. The recipient reads it when they have time.
2. Durability and Replayability:
- Kafka persists messages in a log for a configurable amount of time, so consumers can reprocess messages if they fail or need to recover.
- It’s invaluable for systems requiring fault tolerance or auditability.
Kafka doesn’t just deliver the mail — it keeps a record of every letter ever sent, just in case someone misplaces it.
3. Scalability:
- Kafka is designed to scale horizontally. You can add more brokers (servers) to your Kafka cluster to handle increasing data volume and throughput.
- Topics in Kafka can be split into partitions, allowing multiple consumers to process messages in parallel.
4. Resilience to Failures:
- Even if a consumer service is down, Kafka holds onto the messages. When the service recovers, it picks up right where it left off.
- This resilience reduces the chance of data loss.
Kafka as the Backbone of Event-Driven Systems
In microservices, Kafka is often used to implement event-driven architecture. Here’s how it works:
- Producers emit events to Kafka topics.
- Kafka stores these events as logs, ensuring durability and ordering.
- Consumers subscribe to Kafka topics and process the events asynchronously.
By decoupling producers and consumers, Kafka creates a pub-sub (publish-subscribe) model where multiple services can independently produce and consume messages without knowing about each other.
Key Kafka Features That Make It Perfect for Microservices
- Topics and Partitions
Kafka organizes messages into topics, and each topic can be split into multiple partitions.
- Partitions allow Kafka to scale horizontally because different consumers can process data in parallel.
- Within a partition, Kafka guarantees ordering, which is critical for things like payment processing or event replay.
Topics are like different channels on TV. Partitions are the episodes in the channel. Everyone watching “Partition 2” sees events in the same order.
2. Consumer Groups
Kafka allows consumers to be grouped into consumer groups, enabling load balancing:
- Each consumer in the group processes messages from one or more partitions.
- If a consumer fails, Kafka automatically reassigns the partition to another consumer in the group.
If you have a team of waiters, they’ll divide tables (partitions) among themselves. If one calls in sick, the rest pick up the slack.
3. Fault Tolerance and Durability
- Messages are replicated across multiple brokers (servers), ensuring no data loss even if a node fails.
- Consumers can replay messages from the log as needed, making Kafka ideal for event sourcing.
4. Exactly-Once Semantics (EOS)
For systems that require guarantees (like payments), Kafka supports exactly-once delivery using Kafka transactions.
- Producers and consumers work together to ensure no message is lost or processed more than once.
Real-Life Kafka Use Cases in Microservices
- User Activity Tracking
Kafka excels at collecting user events like clicks, views, and logins. Producers send these events to Kafka, where multiple consumers can process them:
- Analytics Service: Analyzes user behavior.
- Notification Service: Sends relevant notifications based on events.
- Data Warehouse: Stores raw events for long-term analysis.
2. Order Processing in E-Commerce
Let’s say a user places an order. Here’s how Kafka helps decouple services:
- Order Service emits an event: OrderCreated.
- Inventory Service listens for the event, reserves stock, and emits StockReserved.
- Payment Service processes payment.
- Shipping Service handles the shipment.
If any service fails, it can pick up the event again when it recovers, ensuring fault tolerance.
3. Event Sourcing
Kafka acts as a single source of truth for storing events. Instead of persisting just the latest state in a database, services replay events to rebuild state as needed.
If your database is the “current weather report,” Kafka is the historical archive of every weather event that ever happened.
Why Kafka Is Not a Magic Wand
As great as Kafka is, it’s not a silver bullet. There are trade-offs to consider:
- Operational Complexity: Running and managing Kafka clusters requires effort. You’ll need monitoring, scaling, and backup plans.
- Latency: Kafka is fast, but it’s not real-time. There’s always some delay between when an event is produced and consumed.
- Learning Curve: Kafka’s concepts (brokers, topics, partitions, offsets) can be intimidating for newcomers.
Kafka’s a great therapist for microservices, but like real therapists, it charges you in complexity and expects you to commit long-term.
Kafka in a Nutshell
At its core, Kafka solves two major problems for microservices:
- Decoupling: Producers don’t care who consumes the message or when — it’s all asynchronous.
- Reliability: Messages persist, are ordered, and can be replayed.
Kafka enables systems to scale horizontally, handle failures gracefully, and keep services from being tightly interwoven. It’s not magic, but it’s close enough for distributed systems.
Conclusion: Kafka as the Great Mediator
Microservices need Kafka the way noisy roommates need a group chat — it organizes communication, ensures everyone gets the message, and keeps chaos from escalating. Whether you’re building a user activity pipeline, order processing flow, or an event-sourced architecture, Kafka is the backbone that makes it all work.
Of course, Kafka isn’t free — it brings operational challenges and requires careful setup. But once you get the hang of it, your system will feel less like a tangled mess of services yelling at each other and more like a symphony of independent parts working in harmony.
Next time you see microservices getting rowdy, you know who to call. Kafka’s got your back. 🎯
Putting It All Together: Bootstrapping a Scalable System
By now, we’ve discussed the intricacies of system design, the beauty (and pain) of microservices, the practical design patterns that hold everything together, and Kafka’s role as the great mediator of event-driven communication. Now comes the fun part: how to build a scalable system step by step.
Let’s roll up our sleeves and assemble the components into a working architecture that is scalable, fault-tolerant, and ready for the real world.
Step 1: Identify Your Bounded Contexts
The first step in designing a scalable microservice architecture is to identify the bounded contexts — separate logical domains where your system can be split into individual services.
- Break the Monolith:
- Look at your current application (if it’s a monolith). Identify independent components or functionalities like “User Management,” “Orders,” “Payments,” “Notifications,” etc.
- Each bounded context becomes its own microservice.
2. Example E-Commerce System:
- Order Service: Handles creating and managing orders.
- Inventory Service: Tracks stock availability.
- Payment Service: Processes payments securely.
- Notification Service: Sends emails, SMS, or app notifications.
Think of bounded contexts as independent teams in a company: Sales handles clients, HR manages employees, and Finance processes payments. Each has their own role but works toward the same goal.
Step 2: Set Up Kafka as the Communication Backbone
Once you’ve split your system into services, you need a way for them to communicate effectively. Kafka solves this with its pub/sub model for event-driven communication.
How Kafka Fits Into the System:
- Services emit events to Kafka topics when something happens.
- Other services listen to those topics and act on the events.
- Kafka ensures durability, ordering, and scalability.
Example Workflow for an Order Placement:
- Order Service emits an OrderCreated event to the Kafka topic orders:
{ "orderId": "12345", "userId": "6789", "status": "NEW" }- Inventory Service listens to the topic orders and reserves stock for the order. It emits an event StockReserved to the topic inventory.
- Payment Service picks up the StockReserved event and processes the payment.
- Notification Service sends a confirmation email when it sees a PaymentSuccessful event.
Result: Each service is decoupled. The producer (Order Service) doesn’t care if the consumer (Inventory, Payment, Notification) is online or how long it takes to process the message.
Step 3: Add an API Gateway for External Requests
While Kafka handles the internal communication between services, you need an API Gateway to manage external client requests. The API Gateway:
- Routes requests to the correct microservice.
- Aggregates responses if needed (e.g., combining user and order data).
- Handles cross-cutting concerns like authentication, rate-limiting, and caching.
Example Request Flow:
- A user sends an HTTP request to the API Gateway to place an order.
- The Gateway forwards the request to the Order Service.
- Once the Order Service creates the order, it emits an event to Kafka.
- Other services (Inventory, Payment, Notifications) listen to Kafka topics and do their jobs asynchronously.
Tools to Use: NGINX, AWS API Gateway, Kong, or custom solutions with Express.js.
Step 4: Design for Fault Tolerance and Reliability
When building a distributed system, failures are inevitable. Services crash, networks go down, and bugs happen. Kafka already helps by storing messages durably, but you need to implement additional fault-tolerance mechanisms:
- Retries and Dead Letter Queues (DLQ):
- If a consumer fails to process a message after several attempts, send the message to a Dead Letter Queue for later inspection.
- This ensures that a bad message doesn’t block your entire pipeline.
2. Idempotency:
- Ensure that your services can handle duplicate messages gracefully. For example, if the Payment Service receives the same OrderCreated event twice, it should only process the payment once.
3. Monitoring and Alerts:
- Use tools like Prometheus, Grafana, ELK Stack, or Datadog to monitor service health, message lag, and Kafka broker performance.
4. Circuit Breaker Pattern:
- Use libraries like Hystrix or built-in patterns in frameworks to stop cascading failures when a dependent service is down.
Step 5: Optimize Data Storage with CQRS and Event Sourcing
To make your system scalable and performant, separate read and write operations:
- Writes: Use Kafka to persist events as the source of truth.
- Reads: Create a materialized view in a separate database optimized for queries.
Example:
- Orders are written to Kafka as events (OrderCreated, OrderUpdated).
- A consumer reads these events and updates a denormalized table in PostgreSQL, Elasticsearch, or Redis.
- The read model serves fast queries for reporting or APIs.
Benefits:
- Writes remain simple and sequential.
- Reads are fast and optimized for client requests.
Step 6: Scale Horizontally
Scaling in a microservice architecture is straightforward:
- Stateless services: Deploy multiple instances behind a load balancer.
- Kafka partitions: Split topics into multiple partitions to parallelize message consumption.
- Auto-scaling: Use Kubernetes or cloud tools to scale services automatically based on load.
Step 7: Continuous Integration and Delivery (CI/CD)
For a scalable system to remain reliable, you need to automate testing and deployments:
- CI/CD Pipelines: Automate builds, tests, and deployments using GitHub Actions, GitLab CI, or Jenkins.
- Canary Deployments: Gradually roll out new versions to avoid downtime.
- Chaos Engineering: Test how your system handles failures (Netflix’s “Chaos Monkey” is a great inspiration).
Bringing It All Together
Here’s what our architecture looks like now:
- API Gateway: Routes requests to the correct service.
- Kafka: Handles event-driven communication between services.
- Microservices: Stateless, independent services designed around bounded contexts.
- CQRS/Materialized Views: Optimized data storage for fast reads.
- Fault Tolerance: Retries, DLQs, and monitoring ensure reliability.
- Scalability: Auto-scaling and Kafka’s partitioning keep up with load.
- CI/CD Pipelines: Ensure fast, reliable deployments.
The Payoff: A Scalable and Maintainable System
This architecture isn’t just theoretical — it’s battle-tested. Companies like Netflix, Uber, and LinkedIn use similar patterns with Kafka to power their systems, enabling them to handle billions of events per day.
With a solid design and tools like Kafka, you’ve built a system that can:
- Scale effortlessly.
- Recover gracefully from failures.
- Handle massive loads without breaking a sweat.
Final Thought
Building a distributed system is like juggling chainsaws — it looks impressive when done right, but it takes planning, skill, and the right tools. Kafka is your safety net, API gateways are your shields, and these patterns are your roadmap.
Now go forth, architect the next big thing, and remember: the goal isn’t to avoid complexity — it’s to manage it well. 🚀
Step-by-Step: Installing and Setting Up Kafka with Node.js with Docker integration
If you’ve made it this far and are thinking, “Kafka sounds amazing, but where do I start?”, don’t worry. Here’s your cheat sheet to set up Kafka locally and integrate it with a simple Node.js application. This tutorial also covers error handling and Docker integration to make your setup production-ready.
Step 1: Install Kafka Locally
1.1 Install Java
Kafka requires Java (JDK) to run. If it’s not already installed, get it:
sudo apt update
sudo apt install openjdk-11-jdkConfirm installation:
java -version1.2 Download and Set Up Kafka
- Go to the Apache Kafka Downloads page.
- Download the latest Kafka binary (tgz format).
- Extract it:
tar -xvf kafka_*.tgz
cd kafka_*1.3 Start Zookeeper and Kafka
Kafka relies on Zookeeper to manage metadata and broker information. Start Zookeeper and Kafka using these commands:
- Start Zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties2. Start Kafka Broker:
bin/kafka-server-start.sh config/server.propertiesKafka and Zookeeper are now running. You’re officially one step closer to developer greatness.
Step 2: Run Kafka with Docker
To simplify the setup and deployment, we’ll use Docker. Here’s how to run Kafka and Zookeeper using Docker Compose:
2.1 Create a docker-compose.yml file
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPERCLIENTPORT: 2181
ZOOKEEPERTICKTIME: 2000
kafka:
image: confluentinc/cp-kafka:latest
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKABROKERID: 1
KAFKAZOOKEEPERCONNECT: zookeeper:2181
KAFKAADVERTISEDLISTENERS: PLAINTEXT://localhost:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:90922.2 Start the Dockerized Kafka Cluster
Run the following command in the directory where your docker-compose.yml file is located:
docker-compose up -dThis will start both Kafka and Zookeeper in Docker containers.
Step 3: Set Up Node.js and Kafka
3.1 Install Dependencies
In your Node.js project folder, initialize a project and install kafkajs, a simple Kafka library for Node.js:
npm init -y
npm install kafkajsStep 4: Write the Producer Code with Error Handling
Producers send messages to Kafka topics. Here’s how to set one up with added error handling:
producer.js
const { Kafka } = require('kafkajs');
// Initialize Kafka instance
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092'], // Update with your Kafka broker address
});
// Create a producer
const producer = kafka.producer();
const produceMessage = async () => {
try {
await producer.connect();
console.log('Producer connected successfully!');
// Send messages
await producer.send({
topic: 'test-topic',
messages: [
{ key: 'key1', value: 'Hello Kafka!' },
{ key: 'key2', value: 'Node.js meets Kafka' },
],
});
console.log('Messages sent successfully!');
} catch (error) {
console.error('Error in producer:', error);
} finally {
await producer.disconnect();
}
};
produceMessage();Step 5: Write the Consumer Code with Error Handling
Consumers read messages from Kafka topics.
Here’s the consumer with proper error handling and retries:
consumer.js
const { Kafka } = require('kafkajs');
// Initialize Kafka instance
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092'],
});
// Create a consumer
const consumer = kafka.consumer({ groupId: 'test-group' });
const consumeMessages = async () => {
try {
await consumer.connect();
console.log('Consumer connected successfully!');
await consumer.subscribe({ topic: 'test-topic', fromBeginning: true });
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
try {
console.log(`Received: ${message.key}: ${message.value.toString()}`);
} catch (error) {
console.error(`Error processing message ${message.key}:`, error);
}
},
});
} catch (error) {
console.error('Error in consumer:', error);
}
};
consumeMessages();Step 6: Test It All Together
- Open two terminal windows.
- In one terminal, run the producer to send messages:
node producer.js3. In the second terminal, start the consumer to listen for messages:
node consumer.jsIf all goes well, you’ll see the messages sent by the producer being consumed by the consumer:
Received: key1: Hello Kafka from Node.js!
Received: key2: This is message #2🎉 Boom! You’ve just set up Kafka and connected it to a Node.js app.
Step 7: Dockerize Your Node.js Application
To ensure that your Kafka producer and consumer run seamlessly in Docker, create a Dockerfile for your Node.js app:
Dockerfile
# Use an official Node.js image
FROM node:16
# Set the working directory
WORKDIR /usr/src/app
# Copy package.json and install dependencies
COPY package*.json ./
RUN npm install
# Copy the application code
COPY . .
# Expose the application port
EXPOSE 3000
# Start the Node.js app
CMD ["node", "producer.js"] # Change to consumer.js for the consumer container7.1 Build the Docker Image
docker build -t kafka-nodejs-app .7.2 Run the Container
docker run --rm -d --network="host" kafka-nodejs-appStep 8: Monitoring and Logging
Kafka is resilient but needs monitoring. Here are tools you can integrate into your setup:
- Kafka Manager:
- Use tools like Confluent Control Center or Kafka Manager to monitor brokers, topics, and consumer lag.
2. Centralized Logging:
- Add a logging library like winston or pino to capture producer and consumer logs in your Node.js app.
3. Distributed Tracing:
- Integrate OpenTelemetry for tracing across services and Kafka.
Step 9: Test the End-to-End Flow
- Start the Kafka cluster using docker-compose.
- Run your Node.js producer and consumer applications in Docker containers.
- Use the Kafka CLI to check topic data:
docker exec -it kafka kafka-console-consumer --bootstrap-server localhost:9092 --topic test-topic --from-beginning4. Observe messages being produced and consumed with proper logging and error handling.
Step 10: Handling Real-World Scenarios
To take this further:
- Partitioning: Explore how Kafka partitions messages and distribute load.
- Scaling: Add more consumers within the same group to balance the workload.
Conclusion
With Docker, error handling, and monitoring in place, your Kafka setup is scalable, resilient, and ready for real-world use. Whether you’re building a payment gateway, tracking user events, or orchestrating microservices, this setup ensures smooth sailing (or at least fewer late-night debugging sessions).
Kafka setup might seem like lifting a barbell at first, but once you get the hang of it, you’ll realize it’s just another powerful tool in your architecture toolkit. Producers, consumers, and topics are the holy trinity of Kafka, and now you know how to wield them in a Node.js application.
Go ahead, boot up Kafka, send some messages, and feel like a true system architect. Don’t worry if you get a few consumer lag warnings — it’s all part of the journey.
Go build something awesome — and don’t forget to monitor that consumer lag! 🚀
Trade-offs and Lessons Learned: The Price of Going Distributed
In system design, every decision comes with a trade-off. Microservices, Kafka, and all the shiny design patterns are powerful tools, but they don’t come for free. They solve problems, yes, but they introduce new ones that you need to manage carefully.
Let’s take off the rose-colored glasses and talk about the real trade-offs of building a distributed, event-driven system and the lessons learned from those who’ve been through it — sometimes the hard way.
Trade-off 1: Complexity vs. Simplicity
The Problem:
The shift from a monolith to a distributed system adds multiple layers of complexity:
- You now have dozens of services to manage instead of one big codebase.
- Communication between services requires careful orchestration.
- Monitoring, debugging, and deployment become significantly harder.
The Trade-off:
- Monolith: Simple to develop, deploy, and debug initially, but hard to scale.
- Microservices: Easier to scale and evolve, but complex to manage, monitor, and test.
Lesson Learned:
- Don’t over-engineer. Start with a modular monolith (single codebase with separated components). Split into microservices only when scaling or team productivity demands it.
- Use service discovery (like Consul or Eureka) and orchestration tools (Kubernetes) to manage complexity.
Breaking your code into microservices is like moving from one cozy house to a bunch of apartments. Sure, it’s flexible, but now you have to manage plumbing, electricity, and rent payments for each one.
Trade-off 2: Latency vs. Resilience
The Problem:
In a monolith, components communicate in-memory, so requests are fast and reliable. With microservices, every request travels over the network, introducing latency and failure points.
The Trade-off:
- Using synchronous REST APIs is faster but couples services tightly and can fail if one service goes down.
- Using asynchronous messaging with Kafka increases resilience and decouples services but adds latency (you’re waiting for the event to propagate).
Lesson Learned:
- Accept that eventual consistency is the norm in distributed systems. Don’t fight it — embrace it.
- Use timeouts, circuit breakers, and retries to handle failures gracefully. Tools like Hystrix or Resilience4j are your friends here.
- When latency is critical (e.g., payment processing), fall back to a hybrid approach: use synchronous calls where speed matters and Kafka for everything else.
“Real-time” in distributed systems is a myth. The real question is: How ‘eventually’ consistent can you afford to be?
Trade-off 3: Fault Tolerance vs. Complexity
The Problem:
In distributed systems, failures are inevitable:
- A network might go down.
- A Kafka broker might crash.
- A consumer might fail to process a message.
To achieve fault tolerance, you need to design for failure upfront. However, this adds operational and architectural complexity.
The Trade-off:
- Simple systems assume things will work most of the time, but they fail spectacularly when something goes wrong.
- Fault-tolerant systems require retries, dead-letter queues, and replication — but managing them adds cognitive and operational overhead.
Lesson Learned:
- Design with the assumption that everything will fail eventually.
- Use Kafka’s durability and replication to ensure messages aren’t lost.
- Implement dead-letter queues (DLQs) to capture unprocessed messages for debugging later.
A distributed system without fault tolerance is like skydiving without a backup parachute: you’ll regret the decision when you’re falling.
Trade-off 4: Consistency vs. Availability (CAP Theorem)
The Problem:
The CAP Theorem states that in any distributed system, you can only pick two of the following three:
- Consistency: All nodes see the same data at the same time.
- Availability: Every request gets a response (even if it’s not the most recent data).
- Partition Tolerance: The system continues to operate despite network failures.
For a system using Kafka and microservices, partition tolerance is non-negotiable — networks fail, and you need to handle that. This forces you to choose between consistency and availability.
The Trade-off:
- If you prioritize consistency, you may sacrifice availability. Example: A bank transaction where correctness is non-negotiable.
- If you prioritize availability, you accept eventual consistency. Example: Social media “likes” or analytics pipelines.
Lesson Learned:
- Understand your system’s use case. If accuracy matters (payments, inventory), choose consistency. If speed and uptime matter (social feeds, logs), choose availability.
- Kafka makes it easier to achieve eventual consistency by persisting messages and allowing services to replay events.
In distributed systems, you can have 99.9% availability, but your manager will still ask why the other 0.1% happened at 2 a.m.
Trade-off 5: Monitoring vs. Observability
The Problem:
Microservices generate a massive amount of logs, metrics, and traces. Monitoring individual services is no longer enough — you need observability to understand how the entire system behaves.
The Trade-off:
- Simple monitoring works for monoliths but fails to capture distributed workflows across microservices.
- Observability (traces, logs, metrics) gives you deep visibility but requires setting up complex tools like Prometheus, Grafana, and Jaeger.
Lesson Learned:
- Start with centralized logging (e.g., ELK stack) and metrics collection.
- Add distributed tracing (e.g., OpenTelemetry) to visualize request flow across services.
- Monitor Kafka offsets and consumer lag to detect issues early.
Monitoring a distributed system is like watching a swarm of bees. Observability is knowing which bee is carrying the honey and which one got lost in the woods.
Trade-off 6: Operational Overhead vs. Team Flexibility
The Problem:
Microservices allow teams to pick their tech stack, deployment cadence, and infrastructure, offering a level of freedom that’s enticing — but comes at a cost. As more services and technologies are added, the operational burden grows exponentially:
- Dependency Management: Each service needs its own CI/CD pipeline, monitoring, logging, and security measures.
- Knowledge Silos: Developers become highly specialized in a particular service or stack, making cross-team collaboration harder.
- Tool Sprawl: Different teams may choose overlapping or redundant tools, creating chaos in maintenance.
The Trade-off:
- Prioritizing team flexibility fosters innovation but adds operational complexity.
- Prioritizing operational simplicity enforces standardization but can stifle team autonomy.
Lesson Learned:
- Strike a balance with service templates that enforce a base level of standardization (e.g., a shared CI/CD pipeline template, common observability stack).
- Adopt a platform engineering approach where a dedicated team handles cross-cutting concerns like deployment and monitoring.
It’s like giving kids free rein in the kitchen — they’ll create incredible dishes but leave you with a mountain of dirty dishes to clean up.
Trade-off 7: Data Consistency vs. Scalability
The Problem:
Distributed systems often sacrifice strong consistency for scalability and performance. This can lead to:
- Eventual Consistency: Data updates may take time to propagate across services, leading to temporary inconsistencies.
- Stale Reads: Users may see outdated data while systems sync up.
The Trade-off:
- Favoring consistency can slow down the system due to distributed locks or coordination.
- Favoring scalability can lead to edge cases where data isn’t fully consistent.
Lesson Learned:
- Use strong consistency for critical workflows (e.g., financial transactions, inventory updates).
- Use eventual consistency for non-critical data (e.g., analytics, notifications).
- Communicate the trade-offs to stakeholders so they understand the behavior of the system.
“Eventually consistent” is just a fancy way of saying “It’ll work, we promise. Just… not yet.”
Trade-off 8: Real-Time Insights vs. System Performance
The Problem:
As systems grow, the need for real-time insights into logs, metrics, and traces increases. But collecting and processing all this data in real time adds significant overhead to system performance.
The Trade-off:
- Prioritizing real-time insights may slow down the actual services being monitored.
- Prioritizing system performance might mean delays in identifying and resolving issues.
Lesson Learned:
- Use sampling in distributed tracing to reduce the data processed in real time.
- Implement alert thresholds based on anomalies rather than analyzing all data constantly.
- Offload heavy analytics to separate systems, such as ELK (Elasticsearch, Logstash, Kibana) or Prometheus.
It’s like trying to count the raindrops during a storm — you don’t need every drop, just enough to know when it’s flooding.
Trade-off 9: Decoupling vs. Debugging Complexity
The Problem:
Decoupling services improves scalability and fault tolerance but makes debugging harder. With tightly coupled systems, failures are often easier to trace. In decoupled systems, failures may propagate across multiple services, making root cause analysis a nightmare.
The Trade-off:
- Decoupling reduces single points of failure and increases resilience.
- Decoupling makes it harder to trace requests across service boundaries.
Lesson Learned:
- Implement correlation IDs in your requests to trace them across microservices.
- Use distributed tracing tools like Jaeger or OpenTelemetry to visualize service dependencies and bottlenecks.
- Add detailed, contextual logs at key service boundaries to capture critical information.
Decoupling is great until the “decoupled” system makes you feel like you’re solving a murder mystery with no witnesses.
Trade-off 10: Deployment Speed vs. Testing Complexity
The Problem:
Microservices enable fast, independent deployments, but testing becomes exponentially harder. Integration tests must now account for the behavior of multiple services, APIs, and asynchronous communication flows.
The Trade-off:
- Faster deployments can lead to more frequent failures if testing isn’t robust.
- Slower deployments with exhaustive testing reduce agility but minimize risks.
Lesson Learned:
- Use contract testing (e.g., Pact) to validate interactions between services.
- Automate integration tests and run them in isolated staging environments that mirror production.
- Adopt canary deployments to roll out changes incrementally, monitoring for issues before a full release.
Think of deploying microservices like sending spaceships into orbit. Testing every single subsystem is critical, but you still need to monitor for unexpected explosions.
Conclusion: Embrace the Chaos, Manage the Trade-offs
Distributed systems aren’t inherently better or worse — they’re just different. They shift the burden from application complexity to operational complexity. While this trade-off is often worth it for scalability and resilience, success depends on your ability to:
- Identify the right trade-offs for your use case.
- Equip your team with the tools and processes to manage the complexity.
- Constantly re-evaluate your architecture as your system evolves.
In the world of distributed systems, perfection doesn’t exist. The goal is not to eliminate trade-offs but to make them intentional and manageable.
Simplicity Over Complexity: The Golden Rule of System Design
When designing distributed systems, it’s easy to get carried away with trendy tools, fancy architectures, and complex patterns. After all, microservices, event-driven architecture, and Kafka sound cool at conferences. But the reality is that complexity, when not carefully managed, can bury a system — and your team — under an avalanche of operational headaches.
The golden rule? Simplicity first, complexity only when necessary.
Why Is Simplicity Important?
The most successful systems aren’t the most complex — they are the ones that are:
- Easier to understand: If your developers can’t explain the system without drawing a maze on the whiteboard, you have a problem.
- Easier to maintain: Simple systems are cheaper to debug, extend, and operate.
- Easier to scale: Complexity creates bottlenecks — simplicity helps you identify and resolve them faster.
If you need a PhD in Computer Science to explain your architecture, it’s probably not as “genius” as you think.
The Complexity Trap: Shiny Tools and Overengineering
Many teams jump straight into building overly complex architectures under the illusion that “big problems need big solutions.” For example:
- Starting with 50 microservices when one monolith would suffice.
- Using Kafka for every communication flow when a simple REST API would do the job.
- Applying event sourcing or CQRS to a project that doesn’t need heavy scalability.
These decisions don’t come from real needs — they come from the fear of being “under-engineered.” The result?
- Increased operational overhead: Now you’re managing dozens of services, message brokers, and databases.
- Higher cognitive load: Your team spends more time managing infrastructure and debugging communication than solving business problems.
- Unnecessary delays: What could’ve taken weeks to deliver now takes months because of overcomplication.
We implemented Kafka, CQRS, event sourcing, and Kubernetes on Day 1. The service? A to-do list app. It doesn’t work yet, but we’re scaling for the future!
Start Simple: The Modular Monolith
Before splitting your system into microservices, start with a modular monolith — a single codebase with clean boundaries between components.
Benefits of Starting Simple:
- Faster Development: A monolith is easier to set up and deploy early on.
- Easier Debugging: In-memory communication means you avoid network overhead, debugging latencies, and half the headaches of distributed systems.
- Gradual Migration: When you hit scalability limits, you can split components into microservices one by one using the Strangler Fig Pattern.
Example Workflow:
- Build a modular monolith with clear modules like “Orders,” “Payments,” and “Users.”
- Monitor where performance bottlenecks occur or where team boundaries require independence.
- Gradually pull out the most critical modules into microservices.
Building a monolith is like starting with one solid house. If you need more space later, you can add separate guest houses (microservices) as needed.
When to Add Kafka (or Other Complex Tools)
While Kafka is a fantastic tool for decoupling services, it’s not always necessary. Use it when:
- You need to decouple producers and consumers: Services shouldn’t depend on each other’s availability.
- You require fault tolerance: Kafka stores messages durably, so you don’t lose data when services fail.
- Event-driven workflows make sense: For systems like order processing, where multiple services act on the same event, Kafka simplifies the design.
- You have large-scale, high-throughput requirements: Kafka is built to handle billions of events per day without breaking a sweat.
Don’t use Kafka when a simple REST API or synchronous communication will suffice. Adding it too early introduces complexity your team might not be ready to handle.
Kafka is great, but it’s not a requirement to be “modern.” Use tools when they solve a real problem — not when they look good on your architecture diagram.
Practical Strategies to Keep Things Simple
Here’s how you can focus on simplicity without sacrificing scalability or performance:
- Solve for Today, Design for Tomorrow:
- Build what you need now. Design your system with modularity and scalability in mind, but don’t over-engineer for hypothetical future problems.
2. Use the KISS Principle:
- Keep It Simple, Stupid. Resist the urge to add unnecessary tools or frameworks.
3. Start with Synchronous Communication:
- Begin with simple REST or gRPC calls for service communication. Add Kafka or message brokers later when decoupling becomes a necessity.
4. Write Clear, Readable Code:
- Complexity starts at the code level. Write clean, maintainable code so that understanding the system doesn’t require weeks of onboarding.
5. Implement Monitoring Early:
- Simple systems are easier to debug, but you still need logs, metrics, and traces to monitor them. Start small with tools like ELK, Grafana, or Datadog.
6. Prioritize Observability:
- If you’re building microservices, use distributed tracing (OpenTelemetry, Jaeger) to keep visibility over service interactions.
7. Automate Repetitive Tasks:
- Use CI/CD pipelines to automate builds, testing, and deployments. Simplicity doesn’t mean manual processes.
Real-World Example: Netflix’s Gradual Adoption of Microservices
Netflix didn’t wake up one day and decide to split into 1,000 microservices. They started as a monolithic DVD rental platform, but as demand grew, they migrated parts of their system into independent services:
Step 1: Modularize the monolith.
Step 2: Split out the bottlenecks into microservices (e.g., recommendations, user accounts).
Step 3: Gradually move to event-driven architecture with tools like Kafka to decouple services and scale globally.
This gradual migration allowed Netflix to scale effectively without drowning in unnecessary complexity early on.
Simplicity at the start enabled Netflix to experiment, iterate, and scale naturally as demands grew.
Conclusion: Manage Complexity, Don’t Chase It
Complexity in distributed systems is inevitable, but unnecessary complexity is a choice. The key to scalable system design is to:
- Start simple with modular components.
- Introduce tools like Kafka or microservices only when they solve real problems.
- Constantly evaluate trade-offs and keep your architecture as clean and maintainable as possible.
System design is like life — start simple, solve problems as they come, and only bring in the big guns (like Kafka) when you’ve outgrown the small ones. Anything else is just premature optimization disguised as progress. 🚀
How to Reach Out?
📩 Send me a message or email to schedule a consultation.
🎯 Let’s take your system from “it works” to “it scales beautifully.”
The world of distributed systems is complex, but with the right guidance, it’s absolutely manageable. Let’s build something incredible — together. 🚀
Peter Istratov
Email: petr.istratov.exec@gmail.com
Linkedin: https://www.linkedin.com/in/peter-istratov/
Telegram channel: @punk_it_official
